Fast, lightweight, and versatile data streaming.
Stream and process data with a single binary, zero dependencies, and an ultra-low footprint. Get started with Conduit in under 4 minutes.
Deploy anywhere
Conduit is installed as a single binary and requires zero external dependencies – you can stream your data without any intermediaries (such as Apache Kafka) in between. Alternatively, pull the Docker container image, or use our Kubernetes operator for Conduit to install it into your cluster.

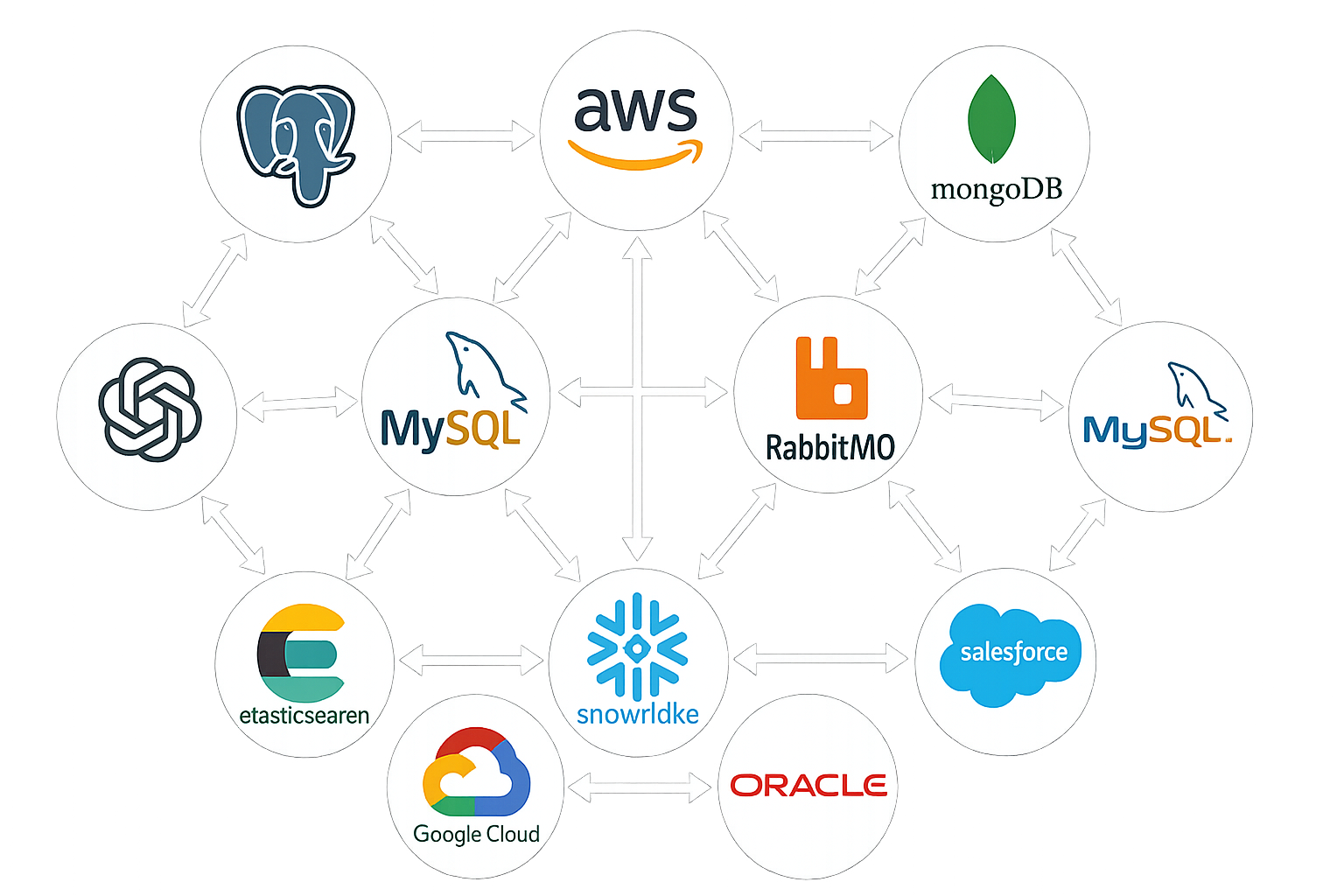
Well Connected
Our ecosystem supports more than 70 systems that you can stream data from or write data into. New connectors are being added all the time. You can also bring a Kafka Connect connector into Conduit. All of our connectors are Apache-2 licensed.
Processors
Conduit features built-in processors that let you apply common data transformations. You can also use JavaScript and HTTP APIs, write a processor in any language using WASM, or scroll down to check out the AI/LLM processors.


AI tooling for pipelines
Your AI assistants and LLM models are most powerful when using the latest data — and that’s exactly what Conduit provides. Read from and write to vector stores such as Weaviate, Pinecone, or the OpenAI vector store. You can use any supported data source to generate embeddings, create text, or apply a Cohere model with the help of the built-in processors.
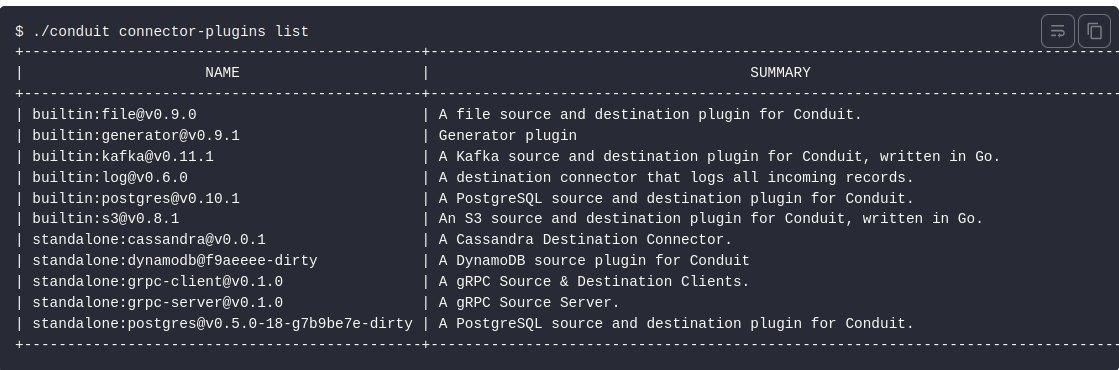
CLI
The Conduit CLI offers an efficient way to initialize and configure Conduit, as well as manage, run, and observe pipelines, connectors, processors, and more.
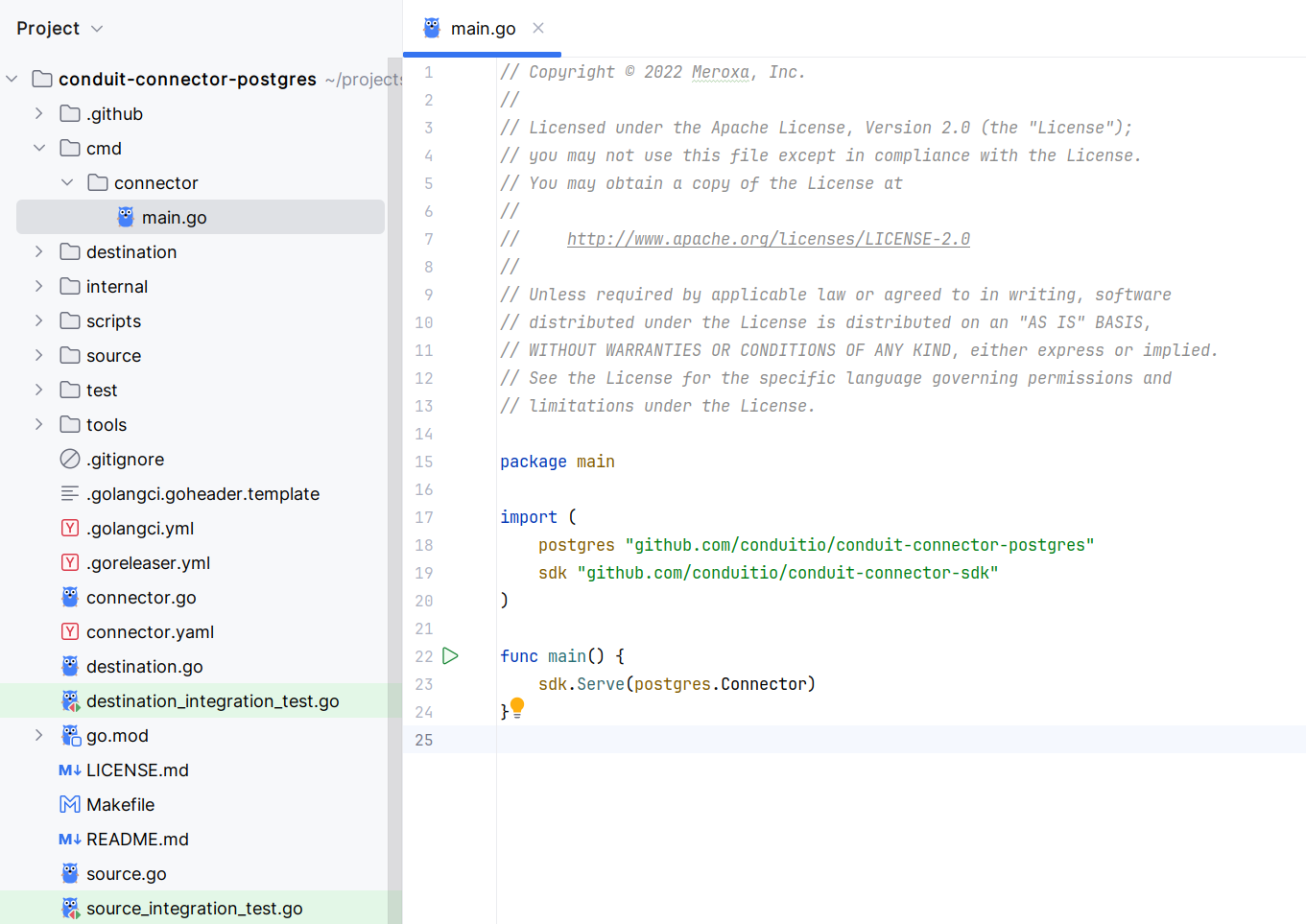
Developer experience
Only minimal knowledge about Conduit is needed to develop a new connector or processor using our SDKs and GitHub repository templates. Conduit and the standalone connectors communicate via gRPC. The Protobuf service definition is open-source, so a connector can be written in any language.
Schema support
To preserve precise information about data types, Conduit supports schema handling either through connector-provided definitions or by generating them automatically. It can manage schemas using its internal schema service or integrate with Confluent's Schema Registry. Learn more in the schema support documentation.
Inspect the data
Troubleshooting isn’t a problem when you can see the data as it’s read from a source, processed by a processor, or written into a destination. Our stream inspector makes it easy to debug your pipeline.


Observability
The HTTP API exposes a Prometheus-compatible metrics endpoint with high-level pipeline, processor and connector metrics, but also Go runtime, gRPC and HTTP API metrics.
Get up.
Get involved.
Get into it.
The Conduit Community is the ultimate resource of information to help you get started and optimize your infrastructure to build and deploy connectors.

